Как построить мост между структурированными и неструктурированными данными?
 Многие компании, в совершенстве овладев работой с классическими данными из корпоративных информационных систем, сегодня сталкиваются с новым вызовом. С развитием электронных каналов продаж у организаций появляются все новые и новые источники информации. По ним поступают целые потоки неструктурированных данных. Их обработка требует совершенно других технологий. Анализ больших данных позволяет делать невозможные ранее открытия, но и от стройных выводов классических данных компании отказываться не хотят. Перед компаниями встает проблема интеграции процессов анализа структурированных и неструктурированных данных.
Многие компании, в совершенстве овладев работой с классическими данными из корпоративных информационных систем, сегодня сталкиваются с новым вызовом. С развитием электронных каналов продаж у организаций появляются все новые и новые источники информации. По ним поступают целые потоки неструктурированных данных. Их обработка требует совершенно других технологий. Анализ больших данных позволяет делать невозможные ранее открытия, но и от стройных выводов классических данных компании отказываться не хотят. Перед компаниями встает проблема интеграции процессов анализа структурированных и неструктурированных данных.
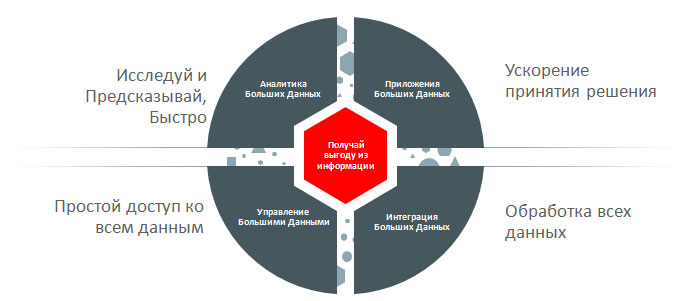
Сегодня ИТ-индустрия предлагает продвинутые решения для работы с большими данными. Технологии Hadoop и NoSQL позволяют анализировать огромные массивы структурированных и неструктурированных данных, но если использовать только их, возникает опасность изоляции больших данных от общей информационной среды компании. Для достижения максимального эффекта необходима интеграция всех типов данных из множества источников, включая Hadoop, реляционные базы данных и NoSQL.
Два мира данных
Чтобы помочь компаниям интегрировать классические и большие данные, производитель программного и аппаратного обеспечения Oracle дополнил свою платформу для работы с большими данными новым продуктом – Oracle Big Data SQL. Он позволяет интегрировать данные разных типов и выполнять один SQL-запрос к данным, содержащимся в Hadoop, NoSQL и Oracle Database. Инновационное решение упрощает доступ к информации, сводит к минимуму перемещение данных, повышает производительность и решает проблему изолированности Big Data.
«Сейчас во всем мире, в том числе и в России, наблюдается рост интереса к обработке сверхбольших объемов данных и технологиям, таким как Hadoop и NoSQL. Эти технологии позволяют вывести обработку больших данных на новый технологический и экономический уровень. Однако эти технологии требуют и новых навыков от разработчиков, но при этом не очень тесно интегрированы с традиционными хранилищами данных и BI-инструментами, — отметил Андрей Пивоваров, руководитель группы перспективных технологий предпроектного консалтинга Oracle СНГ. – Технология Oracle Big Data SQL позволяет решить сразу несколько проблем. Во-первых, разработчики при работе с данными, лежащими в Hadoop и NoSQL, смогут использовать все возможности языка SQL и СУБД Oracle, которые развиваются около 40 лет. Так, разработчики, например, смогут делать запросы к Hadoop прямо из СУБД Oracle. Во-вторых, Big Data SQL позволит строить по настоящему гибридные архитектуры, в которых данные хранятся и в СУБД Oracle, и в кластерах Hadoop или NoSQL. При этом для аналитиков не будет иметь значения, где именно лежат их данные. В запросах можно будет даже объединять данные СУБД Oracle и Hadoop. В-третьих, использование технологии Smart Scan, изначально разработанной для Oracle Exadata, позволит делать ресурсоемкую предобработку петабайтов данных прямо в Hadoop, возвращая в СУБД Oracle только ничтожный объем данных, по сравнению с объемом исходных данных, что позволит ускорять запросы во много раз».
Новое решение по сути позволяет построить универсальный центр управления данными, а также обеспечивает безопасность всей без исключения корпоративной информации. Oracle Big Data SQL распространяет на данные Hadoop и NoSQL средства обеспечения безопасности Oracle Database, включая существующие политики безопасности организации.
«Родной язык» Hadoop – Java – не так распространен среди аналитиков, как SQL. Инновация от Oracle дает возможность эффективно использовать уже сделанные инвестиции в обучение SQL. Сотрудники, используя существующие навыки и опыт, теперь смогут работать и с Hadoop. Соединяя проверенные технологии и упрощая доступ к информации с использованием стандартного для отрасли языка SQL, решение Oracle Big Data SQL позволяет организациям изучать все корпоративные данные и быстрее получать ценные знания для поддержки бизнес-решений. Oracle Big Data SQL разработан для платформы Oracle Big Data Appliance и может работать в связке с Oracle Exadata Database Machine.
«Организации все активнее используют разнообразные источники информации за пределами реляционных баз данных, такие как Hadoop и NoSQL. В результате данные становятся все более разрозненными, что затрудняет их анализ и получение знаний, а также ограничивает реальный потенциал больших данных, — отметил Эндрю Мендельсон (Andrew Mendelsohn), исполнительный вице-президент Oracle по направлению Database Server Technologies. — Oracle Big Data SQL использует популярный, проверенный язык выполнения запросов SQL, чтобы исключить такую изолированность и, в конечном итоге, ввести большие данные в повседневные операции предприятия. Oracle продолжает лидировать по инновациям в управлении базами данных, предлагая организациям этот простой, но мощный способ получения доступа ко всем их данным, эффективного использования существующих инвестиций и навыков, а также получения новых выгод и ценных знаний для трансформации бизнеса».
Эффективно используя SQL для выполнения запросов и анализа данных для традиционных и нереляционных систем управления данными, организациям больше не нужно копировать и перемещать данные между платформами, проводить анализ на базе модели MapReduce или создавать отдельные запросы для каждой платформы, а затем думать, как объединить результаты. Технология Smart Scan от Oracle Exadata выполняет обработку данных локально, обеспечивая интеллектуальный поиск необходимых данных для выполнения конкретного запроса, сводя к минимуму перемещение данных и повышая производительность.
Готовое решение
Высокая конкуренция, стратегия развития электронных каналов продаж, потребность в новых знаниях – эти и другие причины подводят современный бизнес к необходимости анализа больших данных. Зачастую времени на длительные проекты внедрения нет, тогда компании прибегают к облачным сервисам или оптимизированными программно-аппаратным комплексам, которые позволяют быстро начать работу с большими данными.
Так, комплекс Oracle Big Data Appliance дает возможность быстро запустить масштабируемую систему высокой доступности для управления большими массивами данных. Лежащая в основе этой готовой архитектуры платформа оптимизирована как для пакетной, так и для обработки данных в режиме реального времени. Она использует программное обеспечение Cloudera Distribution for Apache Hadoop, Oracle NoSQL Database, Cloudera Impala и Cloudera Search. Это готовое решение позволяет не только сократить сроки внедрения, но и контролировать ИТ-затраты благодаря предварительной интеграции всех аппаратных и программных компонентов. «Oracle Big Data Appliance является превосходным выбором для клиентов, которые хотят работать с полным комплексом передовых Hadoop-технологий Cloudera. Это более экономичный и быстрый в развертывании вариант в сравнении с созданием кластера собственными силами», — заявил Майк Олсон (Mike Olson), основатель, главный статег и председатель совета директоров компании Cloudera.
В компании подсчитали, что Oracle Big Data Appliance позволяет экономить до 39% затрат по сравнению с созданием собственного корпоративного кластера Hadoop. А возросшая емкость хранения и усовершенствованные программные функции Oracle Big Data Appliance позволяют клиентам дополнительно снизить совокупную стоимость владения.
Oracle Big Data Appliance включает полный набор средств для защиты данных и выполнения требований регулирующих органов. Благодаря средствам шифрования хранимых и передаваемых по сети данных, конфиденциальная и регулируемая информация в Oracle Big Data Appliance защищена от краж и несанкционированного доступа. Oracle Big Data Appliance также включает средства корпоративного класса для аутентификации (Kerberos), авторизации (LDAP и проект Apache Sentry) и аудита (Oracle Audit Vault and Database Firewall), которые могут автоматически настраиваться при установке, значительно упрощая процесс защиты Hadoop.
Предварительно протестированные программно-аппаратные комплексы, включающие последние инновационные решения, позволяют компаниям быстро вступить в эру больших данных уже сегодня. Гибкость, конкурентоспособность и эффективность становятся неотъемлемыми характеристиками компаний, управляемых данными.
Big Data на вашем предприятии
Big Data по мнению Oracle